2022. 11. 26. 02:32ㆍ학부 강의/데이터마이닝
1. Test & Score

- CA
: Classification accuracy is the proportion of correctly classified examples. - Precision
: Precision is the proportion of true positives among instances classified as positive, e.g. the proportion of Iris virginica correctly identified as Iris virginica. - Recall
: Recall is the proportion of true positives among all positive instances in the data, e.g. the number of sick among all diagnosed as sick. - F1
: F-1 is a weighted harmonic mean of precision and recall.
이렇게만 보면 잘 모르겠으니깐….
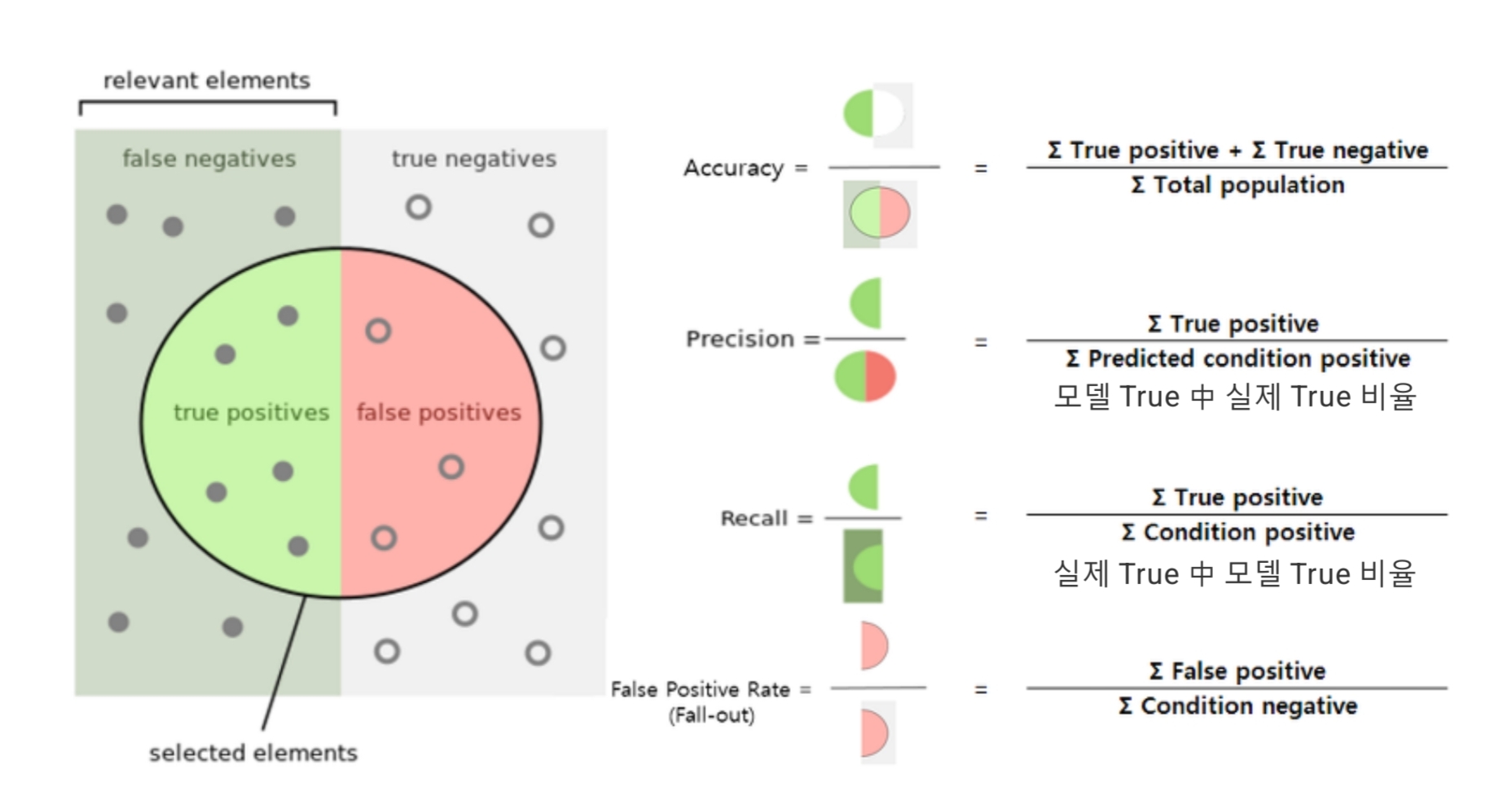
출처 : https://orangedatamining.com/widget-catalog/evaluate/testandscore/
가. 실습
직접 데이터를 구해서 학습시키는 실습을 해보았다.
데이터 출처 : https://www.data.go.kr/data/15070340/fileData.do
주야, 요일, 발생지시도, 가해자법규위반, 도로 형태, 가해자_당사자 종별을 통해서 사고유형을 올바르게 찾아내는지 확인해보자.
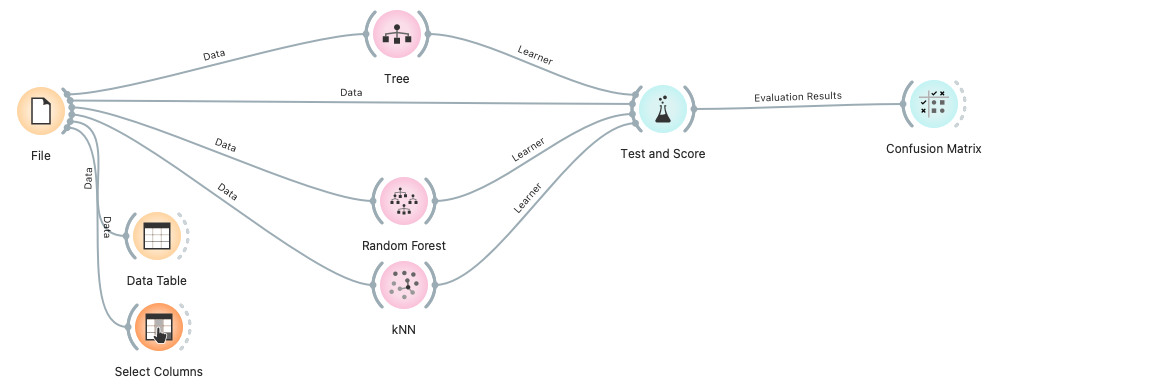
위와 같이 아이콘들을 배치/연결한다.
모델로 Tree, Random Forest. kNN을 사용한다.
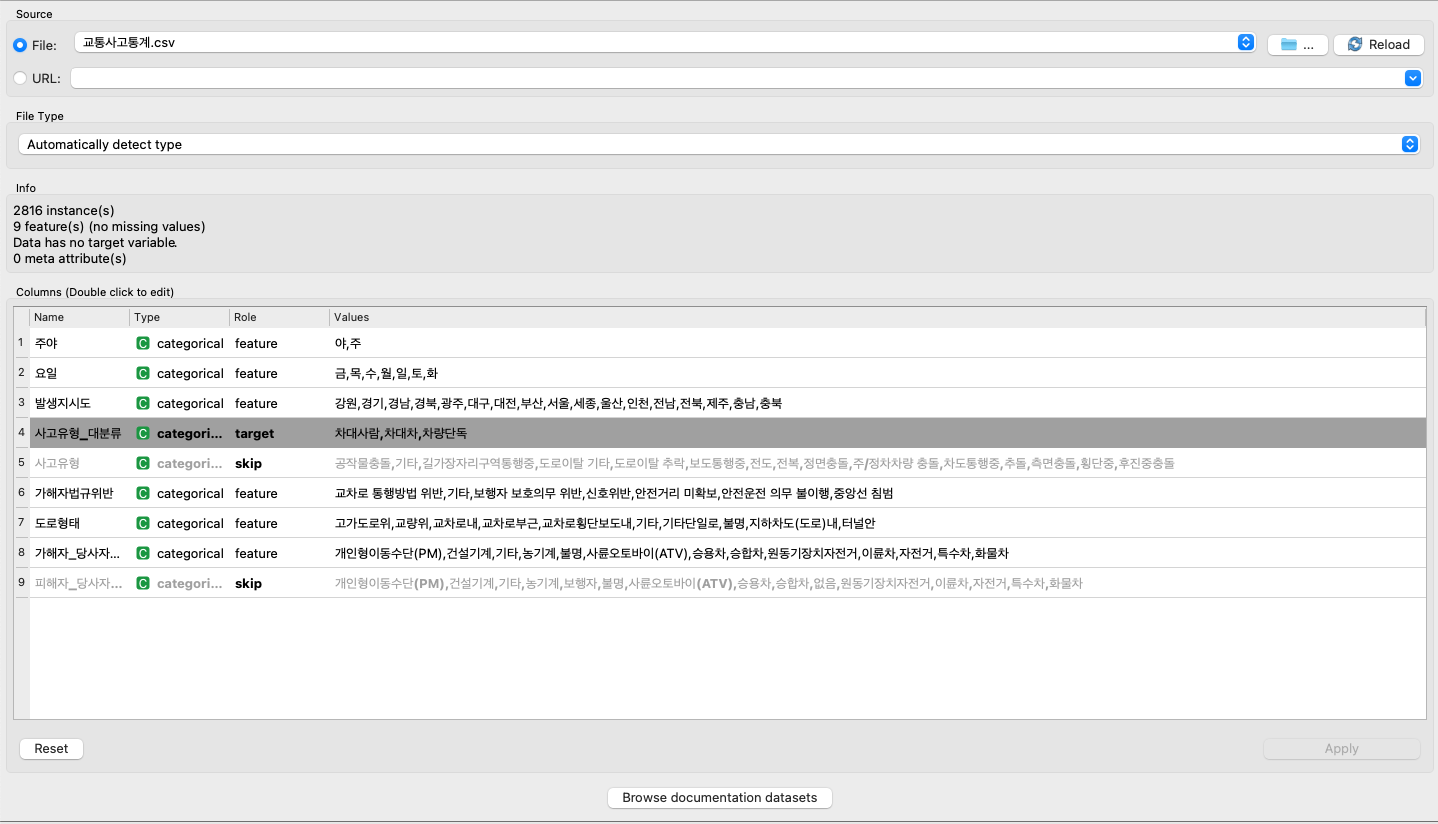
사고 사망 통계의 여러 요소 중 ‘사고유형-대분류’를 타겟하여 진행했다.
너무 결정적인 단서가 될 수 있는 사고유형과 피해자_당사자 종별은 Skip한다.

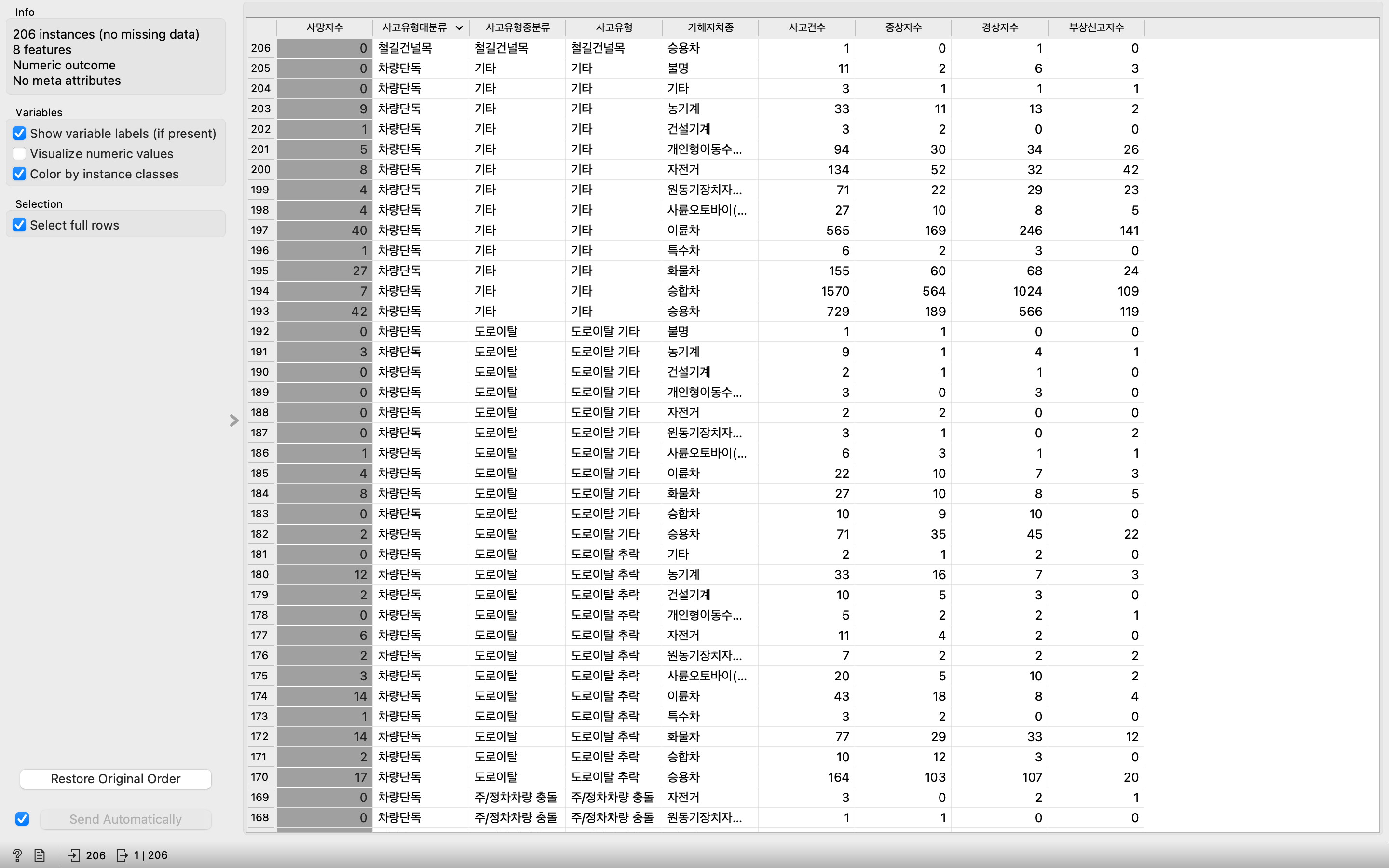
데이터 테이블 확인.
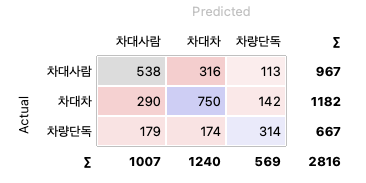
Test&Score와 Confusion Matrix를 통해서 실습의 결과를 확인할 수 있다.
 |
 |
Confusion Matrix를 통해서 Random Forest의 실습 결과를 확인해보면 아래와 같았다.
나. CSV file Import
데이터 수집 : https://www.data.go.kr/data/15070281/fileData.do
한글로 작성된 CSV파일을 import하는 또 다른 방법으로 CSV File Import를 활용할 수 있다.
이때 Encoding 설정을 Korean으로 변경한다.

Select Columns를 이용해서 ‘사망자수’를 target으로 설정할 수 있다.
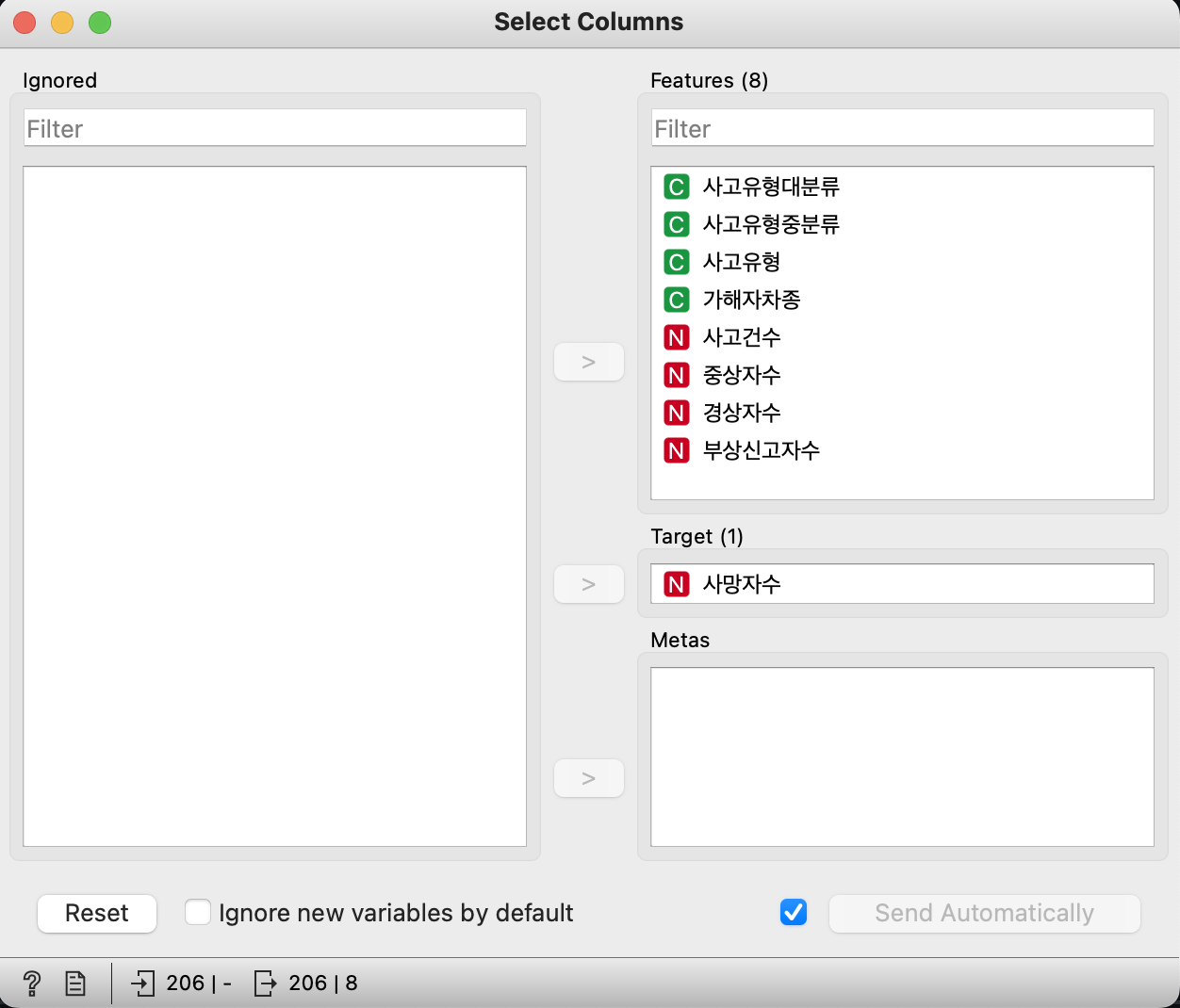
2. image 분석
가. 실습을 위한 Add-ons 설치
앞으로의 실습을 위해서 Educational, Image Analytics, Text를 설치했다.

나. 실습

image embedding은 이미지를 tensor로 변경해준다.
여기서 사용한 Neural Network와 kNN은 지도 학습에 속한다.

디렉터리가 label의 역할을 수행한다.
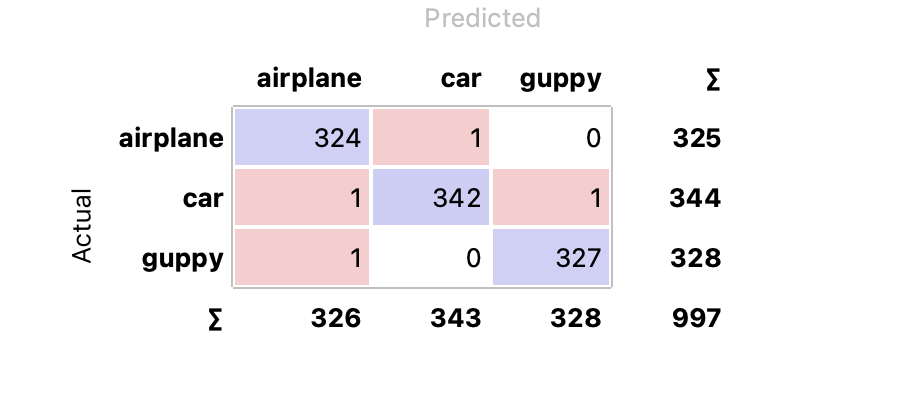
요로코롬 학습이 완료되었다. 각 Matrix를 클릭하고 Image Viewer를 클릭하면 분류에 실패한 이미지를 볼 수 있다.
'학부 강의 > 데이터마이닝' 카테고리의 다른 글
| 2022-11-29 데이터마이닝_11 (0) | 2022.12.18 |
|---|---|
| 2022-11-26 데이터마이닝_10 (0) | 2022.11.27 |
| 2022-11-13 데이터마이닝_8 (0) | 2022.11.13 |
| 2022-11-13 데이터마이닝_7 (0) | 2022.11.13 |
| 2022-10-14 데이터마이닝_6 (0) | 2022.10.14 |