2022. 5. 9. 22:50ㆍBE/Linux
awk
Aho, Weinberger, Kernighan 3명의 개발자 이름에서 첫 글자를 따왔다.
주로 오크라고 발음한다.
유닉스에서 개발된 스크립트 언어다.
원본 문서에서 패턴을 검사해 원하는 값을 얻는다.
각 줄(line)은 레코드(Record), 단어들을 필드(Field)라고 부른다.
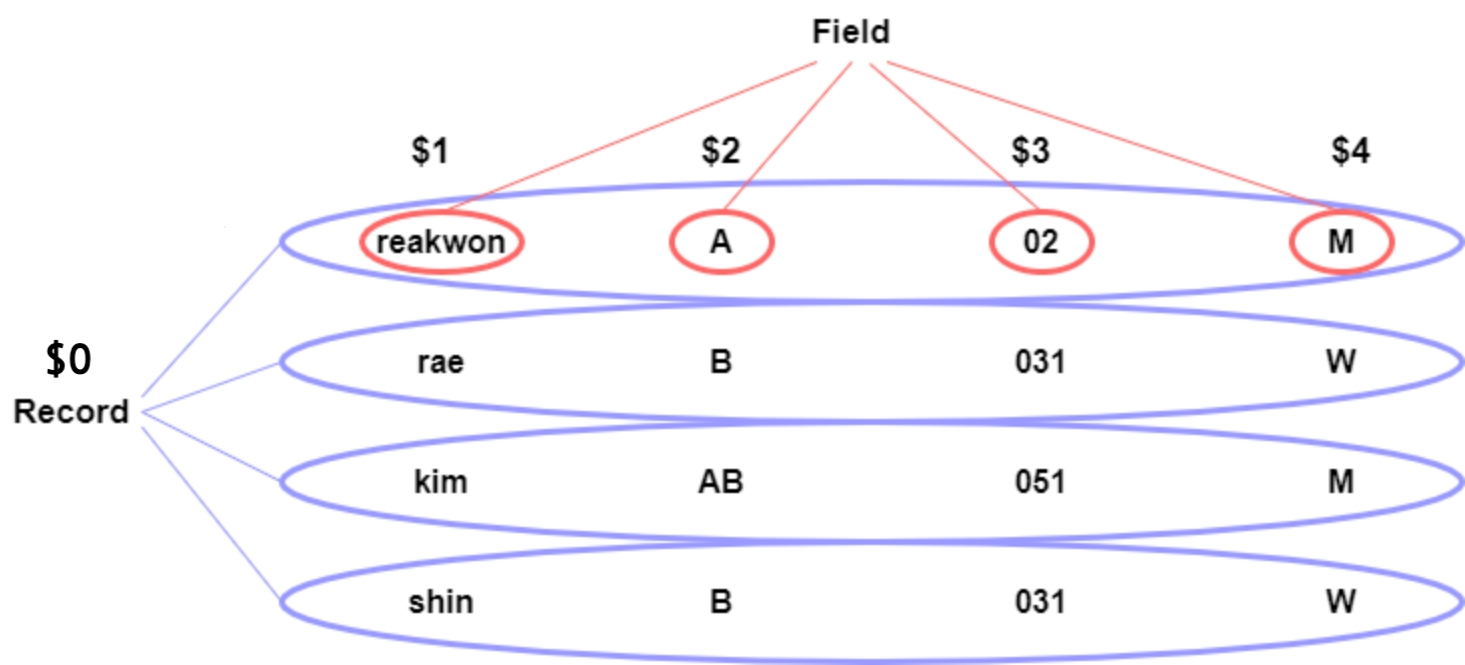
기본적으로 레코드는 줄 바꿈으로 구부하고 필드는 공백으로 구분한다.
참고로 필드구분자를 변경할 수 있는 방법도 있다.
| 옵션 | 설명 |
| -F | 확장된 정규 표현식으로 필드구분자를 지정한다. 다중 필드 구분자 사용이 가능하다. |
| awk -F | 단일로 사용시 ‘:’를 필드구분자로 인식 |
| awk -F'[:\t]' | 다중 필드 구분자 ‘:’와 tab을 필드구분자로 인식 |
awk의 기본 사용법
패턴(pattern)과 액션(action)을 정의하여 입력으로 주어진 파일의 데이터를 가공하여 출력합니다.
awk 'pattern' filename
awk '{ action }' filename
awk 'pattern { action }' filename출처 : https://muabow.tistory.com/entry/awk [이름 같은게 중요 한가요]
예시 파일
name phone age
kim 010-1234-1231 20
lee 010-1234-1232 30
bak 010-1234-1233 40
sung 010-1234-1234 50
jo 010-1234-1235 60패턴만 사용
# 다음의 awk 명령은 kim라는 문자열 패턴이 포함된 레코드를 출력해주는 명령입니다.
awk '/kim/' ./test_file.txt액션만 사용
awk '{ print $1 }' ./test_file.txt # 각 라인의 첫 번째 필드만 출력
awk '{ print $1,$2 }' ./test_file.txt # 각 라인의 첫 번째, 두 번째 필드 출력패턴과 액션 사용
awk '/kim/ { print $2 }' ./test_file.txt패턴은 라인을, 액션은 필드을 선택할 수 있다.
awk 응용
awk '{ print ("name : " $1 ", " "phone : " $2) }' ./test_file.txt
if 구문
awk '{ if ( $3 >= 40 ) print ($0) }' ./test_file.txt
# 또는
awk '$3 >= 40 { print $0 }' ./test_file.txtawk '{ if ( $1 == "jo" ) print ($0); else print ( "noting" ); }' ./test_file.txt
noting
noting
noting
noting
noting
jo 010-1234-1235 60awk '{ if ( $3 >= 40 && $1 == "jo" ) print ($0) }' ./test_file.txt
awk '{ if ( $3 >= 40 || $1 == "jo" ) print ($0) }' ./test_file.txtfor 구문
awk '{ for(i=0;i<2;i++) print( "for loop :" i "\t" $1, $2, $3) }' ./test_file.txtfor loop :0 name phone age
for loop :1 name phone age
for loop :0 kim 010-1234-1231 20
for loop :1 kim 010-1234-1231 20
for loop :0 lee 010-1234-1232 30
for loop :1 lee 010-1234-1232 30
for loop :0 bak 010-1234-1233 40
for loop :1 bak 010-1234-1233 40
for loop :0 sung 010-1234-1234 50
for loop :1 sung 010-1234-1234 50
for loop :0 jo 010-1234-1235 60
for loop :1 jo 010-1234-1235 60
# awk가 작동하는 방식을 알 수 있음.
# awk는 첫 레코드부터 마지막 레코드까지 작업을 반복 수행한다.내장 함수
awk '{ print ("name leng : " length($1), "substr(0,3) : " substr($1,0,3)) }' ./test_file.txtlength() : 단어의 길이
substr(a, b) : a~b까지의 글자 추출
toupper : 대문자로 출력
tolower : 소문자로 출력
... 더 필요한 것이 있으면 구글에 검색해보자.
변수 사용
awk도 하나의 프로그래밍 언어다.
때문에 변수를 사용할 수 있다.
아래는 awk에 기본적으로 내장된 변수들이다.
| 내장 변수 | 설명 |
| FILENAME | 현재 입력파일의 이름 |
| $0 | 입력 레코드 |
| $n | 입력 레코드의 N번째 필드 |
| ENVIRON | 환경변수를 모아둔 관계형 배열 |
| NR | 출력 순번 |
| NF | 현재 줄의 필드수 |
| ARGC | 명령줄의 인자들의 개수 |
| ARGV | 명령줄의 인자들의 배열 |
| FNR | 현재 파일에서의 레코드 번호 |
| FS | 입력 필드 구분자 |
| OFMT | 숫자들의 표현형식 |
| OFS | 출력 필드 구분자 |
| ORS | 출력 레코드 구분자 |
| RS | 입력코드 구분자 |
| EP | 서브스크립트의 구분자 |
| RLENGTH | match 함수로 일치하는 문자열의 길이 |
| RSTART | match 함수로 일치하는 문자열의 오프셋 |
BEGIN, END pattern
awk 'BEGIN { sum = 0 cnt = -1 } { sum += $5 cnt++ } END { avg = sum/cnt print ("sum :" sum ", average :" avg) }' ./test_file.txtawk '
BEGIN {
sum = 0
cnt = -1
}
{
sum += $5
cnt++
}
END {
avg = sum/cnt
print ("sum :" sum ", average :" avg)
}' ./test_file.txtBEGIN은 모든 레코드를 돌기 전에 한번 action을 수행
중간 부분은 첫 번째 레코드에서 마지막 레코드까지 반복해서 실행된다.
END는 모든 레코드를 다 돈 후에 마지막으로 정의한 action이 실행
(name phone age가 존재하기 때문에 cnt = -1로 초기화.)
참고
출처 : https://reakwon.tistory.com/163
출처 : https://muabow.tistory.com/entry/awk
특히 아래의 포스팅은 awk의 거의 모든 것을 정리되어있다!
linux awk 사용법과 예제 설명
awk(오크; Aho Weinberger Kernighan) - awk의 기본 기능은 텍스트 형태로 되어있는 입력 데이터를 행과 단어 별로 처리해 출력하는 것 1. 사용법 Usage: awk [POSIX or GNU style options] -f progfile [--]..
muabow.tistory.com
'BE > Linux' 카테고리의 다른 글
| 리눅스 apt 서버 변경 (0) | 2022.05.17 |
|---|---|
| 2022-05-12 리눅스_디바이스_드라이버_1 (0) | 2022.05.12 |
| 리눅스 원격 서버 파일 송수신 (0) | 2022.05.06 |
| 2022-05-06 리눅스_사용자_생성_관리_전환 (0) | 2022.05.06 |
| [네이버 클라우드] 1년간 무료 리눅스 서버 구축하기 (0) | 2022.05.05 |