2022-09-20 데이터마이닝_2
2022. 9. 20. 22:30ㆍ학부 강의/데이터마이닝
변수 생성
> english <- c(90, 80, 60, 70) #영어 점수 변수 생성
> english[1] 90 80 60 70
> math <- c(50,60,100, 20) #수학 점수 변수 생성
> math[1] 50 60 100 20
c() : 데이터나 객체를 하나로 결합(Conbine)하는 함수.
데이터 프레임 생성
> #english, math로 데이터 프레임 생성해서 df_midterm에 할당
> df_midterm <- data.frame(english, math)
> df_midterm
english math
1 90 50
2 80 60
3 60 100
4 70 20
데이터 호출
> df_midterm
english math
1 90 50
2 80 60
3 60 100
4 70 20> df_midterm$english
[1] 90 80 60 70
데이터 평균 구하기
> mean(df_midterm$english) # 영어 평균
[1] 75
> mean(df_midterm$math) # 수학 평균
[1] 57.5
데이터 프레임 복사
> df_new <- df_midterm
변수 이름 바꾸기
> df_new <- rename(df_new, en = english)
# df_new 데이터 프레임의 english를 en으로 이름 바꿈
변수 및 데이터 프레임 삭제
> rm(class)
데이터 파악하기
데이터를 가지고 노는 방법 6가지를 더 알아보자.
준비
exam <- read.csv("car_house.csv")
가. head()
> head(exam) # 앞에서부터 6행 출력
AGE CAR NEW_CAR MONEY HOME MARRY
1 36 1 1 700 1 Yes
2 41 1 1 300 1 Yes
3 35 1 0 400 1 Yes
4 31 1 0 700 1 No
5 28 1 1 500 1 No
6 25 1 1 300 1 No
> head(exam, 10) # 앞에서부터 10행 출력
AGE CAR NEW_CAR MONEY HOME MARRY
1 36 1 1 700 1 Yes
2 41 1 1 300 1 Yes
3 35 1 0 400 1 Yes
4 31 1 0 700 1 No
5 28 1 1 500 1 No
6 25 1 1 300 1 No
7 33 1 1 300 0 Yes
8 54 1 1 400 1 Yes
9 31 1 1 250 0 No
10 28 2 1 700 1 Yes
데이터 앞부분 출력
나. tail()
> tail(exam) # 뒤에서부터 6행 출력
AGE CAR NEW_CAR MONEY HOME MARRY
995 54 1 1 700 1 Yes
996 33 1 1 450 1 Yes
997 30 1 1 150 0 No
998 30 1 1 500 1 No
999 41 1 1 700 0 Yes
1000 34 1 1 500 0 Yes
> tail(exam, 10) #뒤에서부터 10행 출력
AGE CAR NEW_CAR MONEY HOME MARRY
991 46 2 1 500 1 No
992 52 1 1 350 0 Yes
993 48 1 1 700 0 Yes
994 47 1 1 700 1 No
995 54 1 1 700 1 Yes
996 33 1 1 450 1 Yes
997 30 1 1 150 0 No
998 30 1 1 500 1 No
999 41 1 1 700 0 Yes
1000 34 1 1 500 0 Yes
데이터 뒷부분 출력
다. View()
View(exam)
# 대문자 주의
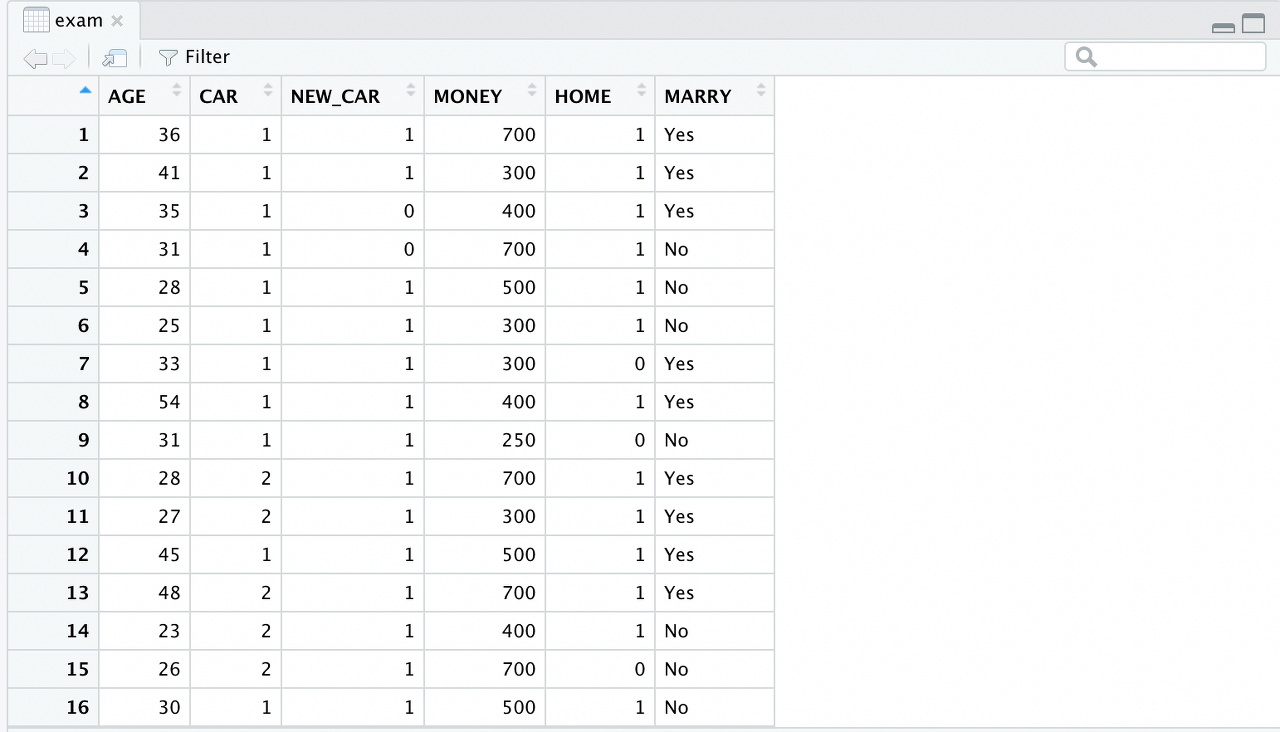
뷰어 창에서 데이터 확인
편하게 데이터를 볼 수 있다.
라. dim()
> dim(exam)
[1] 1000 6
# 1000개의 행과 6개의 열
데이터 차원 출력
마. str()
> str(exam)'data.frame': 1000 obs. of 6 variables:
$ AGE : int 36 41 35 31 28 25 33 54 31 28 ...
$ CAR : int 1 1 1 1 1 1 1 1 1 2 ...
$ NEW_CAR: int 1 1 0 0 1 1 1 1 1 1 ...
$ MONEY : int 700 300 400 700 500 300 300 400 250 700 ...
$ HOME : int 1 1 1 1 1 1 0 1 0 1 ...
$ MARRY : chr "Yes" "Yes" "Yes" "No" ...
데이터 속성 출력
바. summary()
> summary(exam)
AGE CAR NEW_CAR MONEY HOME MARRY
Min. :20.00 Min. :1.000 Min. :0.000 Min. :150 Min. :0.000 Length:1000
1st Qu.:33.00 1st Qu.:1.000 1st Qu.:1.000 1st Qu.:350 1st Qu.:0.000 Class :character
Median :39.50 Median :1.000 Median :1.000 Median :450 Median :1.000 Mode :character
Mean :40.05 Mean :1.196 Mean :0.874 Mean :466 Mean :0.665
3rd Qu.:46.00 3rd Qu.:1.000 3rd Qu.:1.000 3rd Qu.:500 3rd Qu.:1.000
Max. :75.00 Max. :3.000 Max. :1.000 Max. :700 Max. :1.000
요약통계량 출력
파생 변수
> df_midterm$sum <- df_midterm$english + df_midterm$math
> df_midterm
english math sum
1 90 50 140
2 80 60 140
3 60 100 160
4 70 20 90
df_midterm이란 프레임에서 english와 math의 값을 더해서 sum이라는 변수를 만든다.
외부 데이터 이용하기
install.packages("readx1")
library(readx1)가. excel 읽어오기
df_excel <- read_excel("excel_name.xlsx")df_excel <- read_excel("excel_name.xlsx", col_names = F)
# 엑셀의 첫 번째 행이 변수명이 아니라면
df_excel <- read_excel("excel_name.xlsx", sheet = 3)
# 엑셀의 시트수가 3개일때
'학부 강의 > 데이터마이닝' 카테고리의 다른 글
| 2022-10-14 데이터마이닝_6 (0) | 2022.10.14 |
|---|---|
| 2022-10-06 데이터마이닝_5 (0) | 2022.10.06 |
| 2022-09-28 데이터마이닝_4 (0) | 2022.09.28 |
| 2022-09-21 데이터마이닝_3 (1) | 2022.09.21 |
| 2022-09-13 데이터마이닝_1 (0) | 2022.09.14 |