2022. 9. 28. 22:58ㆍ학부 강의/데이터마이닝
의사결정 트리 (Decison Tree)
결정 트리(decision tree)는 의사 결정 규칙과 그 결과들을 트리 구조로 도식화한 의사 결정 지원 도구의 일종이다.
모델 학습 시 각 변수마다 중요도(feature importance)를 계산한다.
출처 : https://data-make.tistory.com/75
출처 : https://ko.wikipedia.org/wiki/결정_트리
조건부 추론 트리 (Conditional Inference Tree)
조건부 추론 트리는 의사결정 트리(Decision Tree) + 통계적 유의성 확인(변수의 유의성)이 가능한 수치를 제공해주는 Tree다.
의사결정 나무 알고리즘에서 발생하는 두 가지 단점 해결
- 통계적 유의성에 대한 판단 없이 노드를 분할하면서 생기는 과적합 문제 극복
- 다양한 값으로 분할 가능한 변수가 다른 변수에 비해 선호되는 문제
통계적으로 칼럼 별 중요도를 파악.
중요도가 큰 변수를 트리의 상위에 배치하여 인과관계를 조금 더 정확하게 판별할 수 있다.
출처 : https://data-make.tistory.com/80
예시 1
준비
df <- read.csv('car_house.csv', stringsAsFactors = TRUE)
str(df)
head(df)필요한 데이터를 로드하여 df에 저장
install.packages("caret")
install.packages("party")
install.packages("e1071")실습에 필요한 패키지 설치
- caret : Classification And Regression Training. 예측 모델을 만들기 위한 프로세스를 간소화하는 일련의 함수입니다.
- party : 재귀 파티셔닝을 위한 계산 툴 박스다. 패키지의 핵심은 ctree()다. (조건부 추론 트리)
- e1071 : 확률과 통계에 대한 기타 함수를 포함. 없어도 되지만 간혹 오류가 생겨서 일단 설치해봄.
출처 : https://topepo.github.io/caret/
출처 : https://cran.r-project.org/web/packages/party/index.html
출처 : https://cran.r-project.org/web/packages/e1071/index.html
library(caret)
library(party)실습에 필요한 패키지 라이브러리 로드
set.seed(2000)랜덤 추출을 위한 값 배정
재현 가능한 랜덤값을 얻기 위해서 필요하다. (ex. 마크 맵 시드 번호)
파티션 생성
intrain <- createDataPartition(y=df$MARRY, p = 0.7, list = FALSE)70%와 30%로 나누겠다. (하나는 모델 생성에, 하나는 모델 평가에 사용할 예정)
데이터를 MARRY 기준으로 70%를 랜덤 추출한다.
partition은 intrain에 저장함.
 |
 |
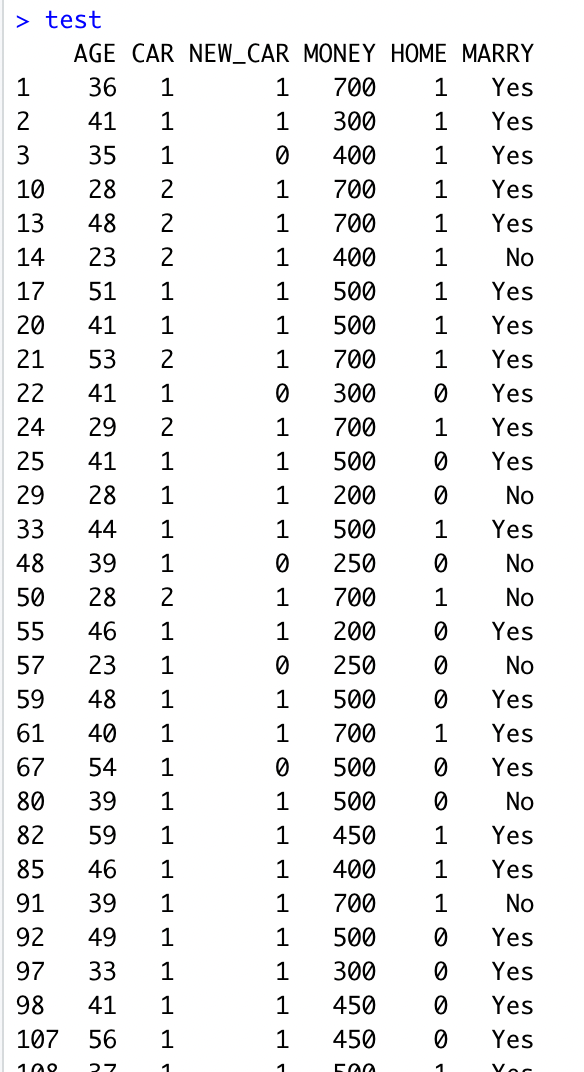
train <- df[intrain,]
# 위 단계에서 추출한 데이터를 train에 저장 (전체의 70%)
test <- df[-intrain,]
# train에 저장되지 않은 나머지 값을 저장 (전체의 30%) |
 |
df[infrain,]에 ,가 없으면 안 된다.
그러면 ,는 무슨 의미인가?
예시로 사용할 df_midterm은 아래와 같다.
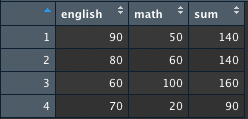
> df_midterm[1] # 1번 열(세로줄)
english
1 90
2 80
3 60
4 70
> df_midterm[1,] # 1번 행(가로줄)
english math sum1
90 50 140
> df_midterm[1,1] # 1번 행 & 1번 열
[1] 90
> df_midterm[,1] # 1번 열(세로줄)을 가로로 나열
[1] 90 80 60 70
R에서 데이터 프레임을 인덱싱하는 방법이 따로 있는 것 같다. (참고 : https://ordo.tistory.com/10)
필요하면 외우자.
어쩔 수 없다.
트리 생성
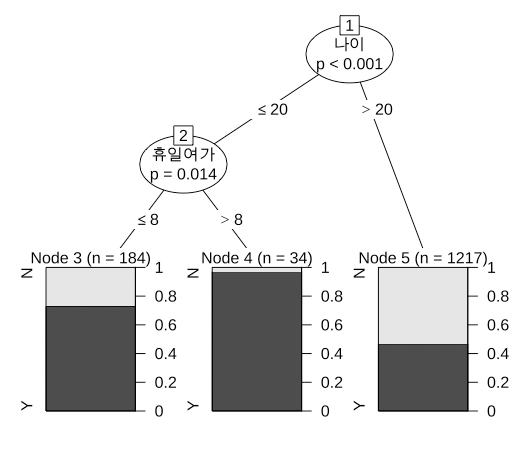
partymod <- ctree(MARRY~., data = train)dicision tree를 작성하기 위해 ctree 기능을 활용하여 작성.
MARRY를 기준으로 트리를 작성하고 partymod에 결과를 저장함.
MARRY~.: 파일에 포함되는 모든 항목 사용MARRY~ MONEY+HOUSE: 특정 항목 MARRY, MONEY, HOUSE만 사용.
plot(partymod)화면에 트리를 출력

위에서부터 결혼에 영향을 많이 주는 요소다.
AGE가 31세보다 적은 지 많은지가 결혼 여부에 가장 큰 영향을 준다.
또 나이가 26세보다 적고 많은지, 나이가 39세보다 많고 적은 지, 돈을 300보다 많이 버는지 적게 버는지가 결혼에 영향을 준다.
테스트
partypred <- predict(partymod, test)이전에 30%의 데이터를 따로 test에 넣어놓았다.
이를 이용하여 partymod와 비슷한 결괏값을 가질지 시험해보자.
작성된 트리를 test 데이터에 적용하여 예측을 실시하고 결괏값을 partypred에 저장
confusionMatrix(partypred, test$MARRY)예측한 결과(partypred)와 실제 정답(test$MARRY)의 유사도 측정

table(partypred, test$MARRY)예측 결과와 실제 정답 간의 오차 확인

예측은 no가 53명, yes가 246명이다.
실제로는 no가 89명, yes가 210명이다.
잘못 예측된 값은 yes지만 no로 예측한 10명과 no지만 yes로 예측한 46명이다.
참고 : ctree함수로 작성한 의사결정나무 결과 해석
ctree함수로 작성한 의사결정나무 결과 해석
1. party패키지의 ctree함수란? 의사결정나무를 생성하는데는 3가지 방법이 있다. 함수 특징 tree( )함수 b...
blog.naver.com
예시 2
자취를 한다면 어떤 요인이 중요하게 작용하는지 알아보자.
library(caret)
library(party)
df2 <- read.csv('home_std2.csv', stringsAsFactors = TRUE)
set.seed(2000)
intrain2 <- createDataPartition(y=df2$형태, p = 0.7, list = FALSE)
train2 <- df2[intrain2,]
# 위 단계에서 추출한 데이터를 train2에 저장 (전체의 70%)
test2 <- df2[-intrain2,]
# train2에 저장되지 않은 나머지 값을 저장 (전체의 30%)
partymod2 <- ctree(형태~., data = train2)
plot(partymod2)
한글 깨짐 ㅅㄱ. 아 제발요…
partypred2 <- predict(partymod2, test2)
confusionMatrix(partypred2, test2$형태)
table(partypred2, test2$형태)
예시 3
library(caret)
library(party)
df3 <- read.csv('volunteer.csv', stringsAsFactors = TRUE)
set.seed(2000)
intrain3 <- createDataPartition(y=df3$봉사활동, p = 0.7, list = FALSE)
train3 <- df3[intrain3,]
# 위 단계에서 추출한 데이터를 train2에 저장 (전체의 70%)
test3 <- df3[-intrain3,]
# train2에 저장되지 않은 나머지 값을 저장 (전체의 30%)
partymod3 <- ctree(봉사활동~., data = train3)
plot(partymod3)
폰트 깨짐
Rstudio에서 폰트를 사용할 수 있게 설치하겠다.
install.packages('extrafont')
library(extrafont)
fonts() # 현재 사용할 수 있는 폰트 이름
fonttable() # 현재 사용할 수 있는 폰트 자세한 정보
font_import()
# font_import(pattern = "AppleGothic") 특정 폰트만 선택No Font Name Skipping이라고 뜨면서 오류가 발생한다.
이에 extrafont가 아닌 showtext를 사용해서 font를 가져오자.
install.packages('showtext')
library('showtext')
font_families() # 사용가능한 폰트 조회
font_add_google('Nanum Gothic', 'Nanum Gothic')
# 'Nanum Gothic' 글꼴을 설치하고, 이를 'Nanum Gothic'으로 부르겠다.
showtext_auto()
par(family = "Nanum Gothic")
정의는 승리한다!
출처 : https://funnystatistics.tistory.com/18

'학부 강의 > 데이터마이닝' 카테고리의 다른 글
| 2022-10-14 데이터마이닝_6 (0) | 2022.10.14 |
|---|---|
| 2022-10-06 데이터마이닝_5 (0) | 2022.10.06 |
| 2022-09-21 데이터마이닝_3 (1) | 2022.09.21 |
| 2022-09-20 데이터마이닝_2 (0) | 2022.09.20 |
| 2022-09-13 데이터마이닝_1 (0) | 2022.09.14 |