2022. 10. 6. 01:07ㆍ학부 강의/데이터마이닝
1. Random Forest
기계 학습에서의 랜덤 포레스트는 분류, 회귀 분석 등에 사용되는 앙상블 학습 방법의 일종이다.
훈련 과정에서 구성한 다수의 결정 트리로부터 부류(분류) 또는 평균 예측치(회귀 분석)를 출력함으로써 동작한다.
( 출처 : https://ko.wikipedia.org/wiki/랜덤_포레스트 )
Decision Tree는 overfitting될 가능성이 높다는 약점을 가지고 있다.
가지치기를 통해 트리의 최대 높이를 설정해 줄 수 있지만 overfitting을 충분히 해결할 수 없다.
그러므로 좀더 일반화된 트리를 만드는 방법을 생각해야한다.
이에 Random Forest(랜덤 포레스트)가 사용된다.
Random forest는 ensemble(앙상블) machine learning 모델이다.
랜덤 포레스트가 생성한 일부 트리는 overfitting될 수 있지만, 많은 수의 트리를 생성함으로써 overfitting을 해결한다.( 출처 : https://eunsukimme.github.io/ml/2019/11/26/Random-Forest/ )
임의의 여러 개의 Decision tree를 만들기에 Random forest라고 하는 것 같다.
Random Forest의 구체적인 원리는 수업의 취지를 벗어나기에 배우지 않았다.
추후에 필요하다면 원리에 대하여 따로 공부하자.
과적합 문제 (Overfitting)
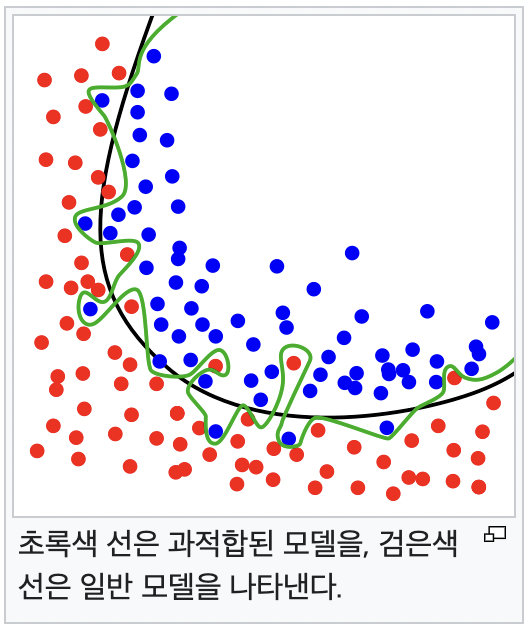
과적합 또는 과대 적합은 기계 학습에서 학습 데이터를 과하게 학습(overfitting)하는 것을 뜻한다.
일반적으로 학습 데이터는 실제 데이터의 부분 집합이므로 학습 데이터에 대해서는 오차가 감소하지만 실제 데이터에 대해서는 오차가 증가하게 된다.
출처 : https://ko.wikipedia.org/wiki/과적합
실습
install.packages("randomForest")
library(randomForest)randomForest 패키지 설치
treemod <- randomForest(MARRY~., data= train, mtry=5, ntree=1000)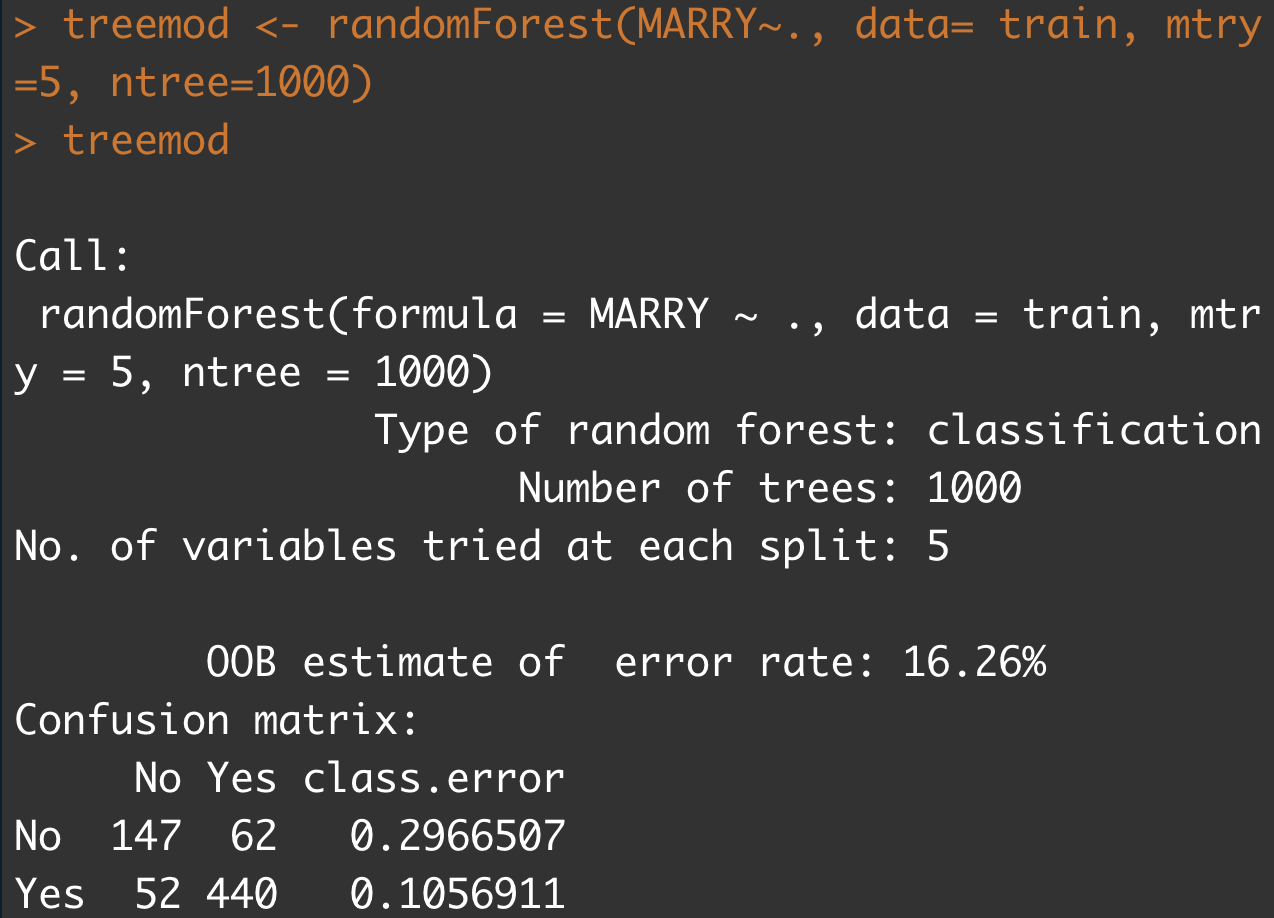
MARRY~.: MARRY를 기준으로 다른 모든 요소들과의 연관관계를 파악한다.ntree=1000: 임의의 트리를 1000개 생성mtry=5: 각 분할에서 후보로 랜덤하게 표본 추출될 변수의 수
이외에도 많은 Argument가 있으니 참고해라.
randomForest reference pdf file : https://cran.r-project.org/web/packages/randomForest/randomForest.pdf
importance(treemod)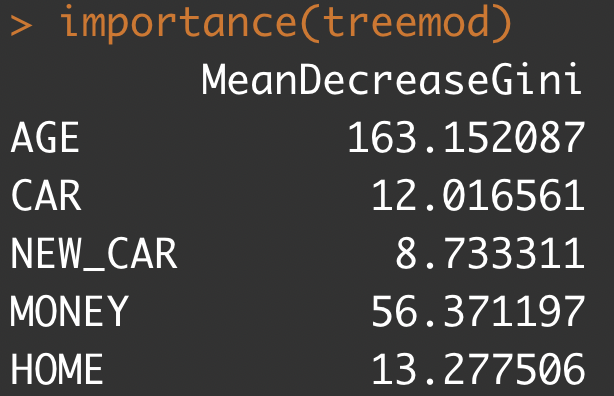
importance(x, type=NULL, class=NULL, scale=TRUE, ...): randomForest에서 제공하는 변수 중요도 측정을 위한 추출 함수이다.
어느 변수가 중요한 요소인지 알 수 있다.
출처 : https://www.rdocumentation.org/packages/randomForest/versions/4.7-1.1/topics/importance
varImpPlot(treemod)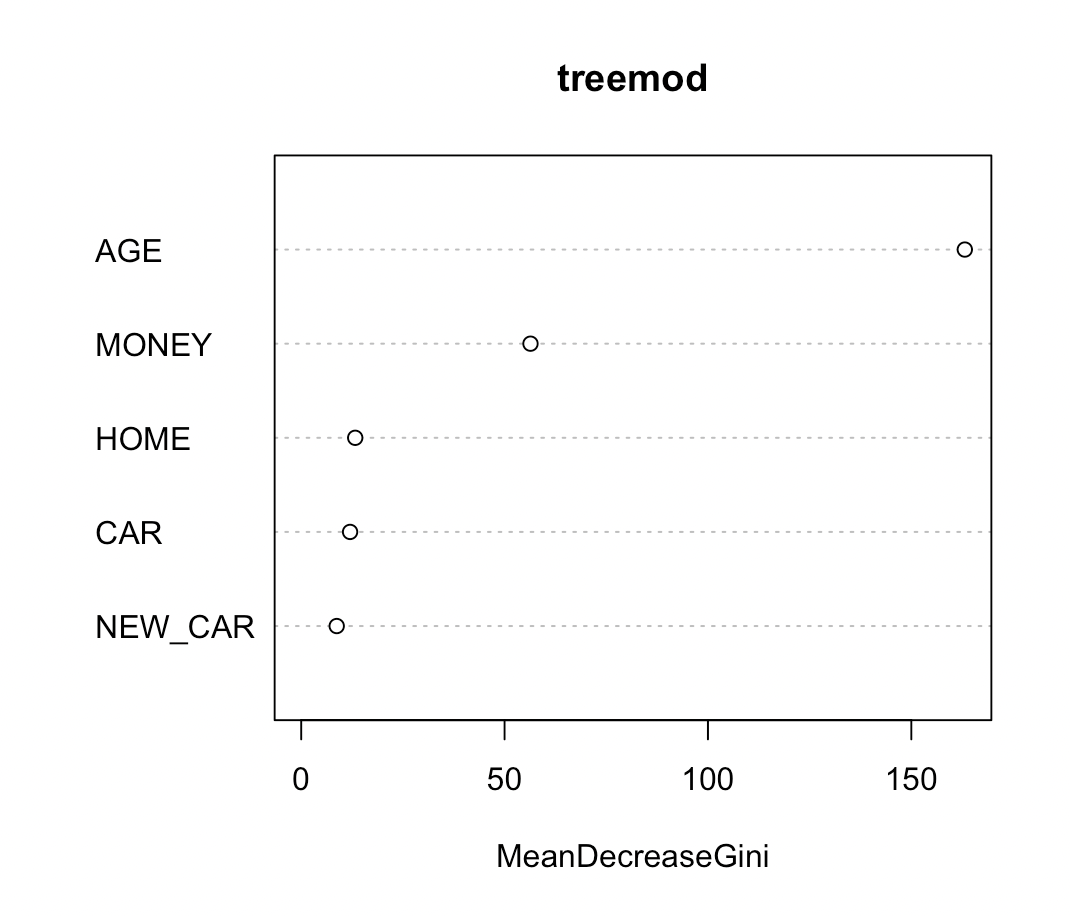
varImpPlot(): 점도표로 나타낸 변수별 중요도. (Dotchart of variable importance as measured by a Random Forest.)
출처 : https://www.rdocumentation.org/packages/randomForest/versions/4.7-1.1/topics/varImpPlot
partypred <- predict(treemod, test)
library(caret)
confusionMatrix(partypred, test$MARRY)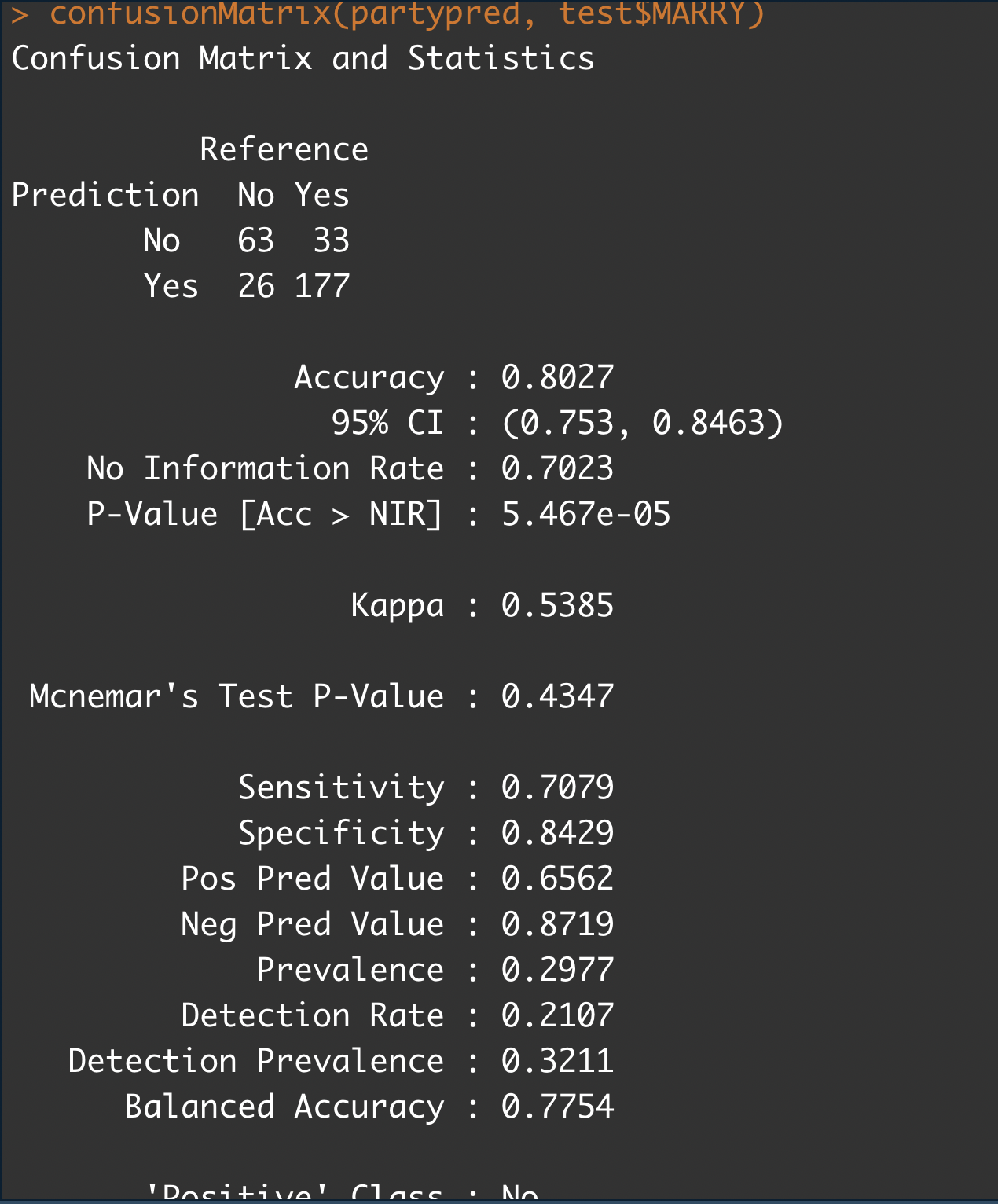
테스트
2. 인공신경망
AI 입문 단층 신경망 강의 내용을 참고하면 좋을 것 같다.
이전 포스트 : (https://ramen4598.tistory.com/176)
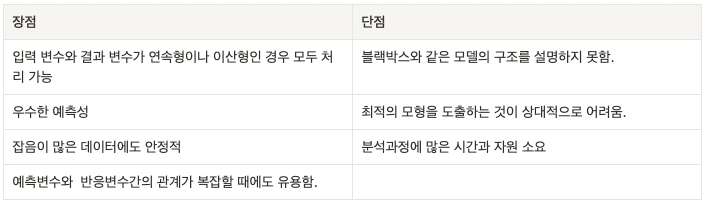
인공신경망의 장단점
실습
install.packages("nnet")
install.packages("NeuralNetTools")
library(caret)
library(nnet)
library(NeuralNetTools)
nnet: Software for feed-forward neural networks with a single hidden layer, and for multinomial log-linear models.
(하나의 은닉층을 가지는 feed-forward 뉴럴 네트워크와 다항 로그 선형 모형을 지원하는 소프트웨어.)
NeuralNetTools
: Visualization and analysis tools to aid in the interpretation of neural network models. Functions are available for plotting, quantifying variable importance, conducting a sensitivity analysis, and obtaining a simple list of model weights.
(해석에 도움이 되는 시각화 및 분석 도구. 신경망 모델 플롯, 변수 중요도 정량화, 민감도 분석 수행, 간단한 모델 가중치 리스트를 획득하는 기능을 사용할 수 있다.)
출처 : https://www.rdocumentation.org/packages/nnet/versions/7.3-18
출처 : https://www.rdocumentation.org/packages/NeuralNetTools/versions/1.5.3
df <- read.csv('fat_bmi2.csv', stringsAsFactors = TRUE)
intrain <- createDataPartition(y=df$condition, p=0.7, list = FALSE)
train <- df[intrain,]
test <- df[-intrain,]train과 test로 학습 데이터를 나눈다.
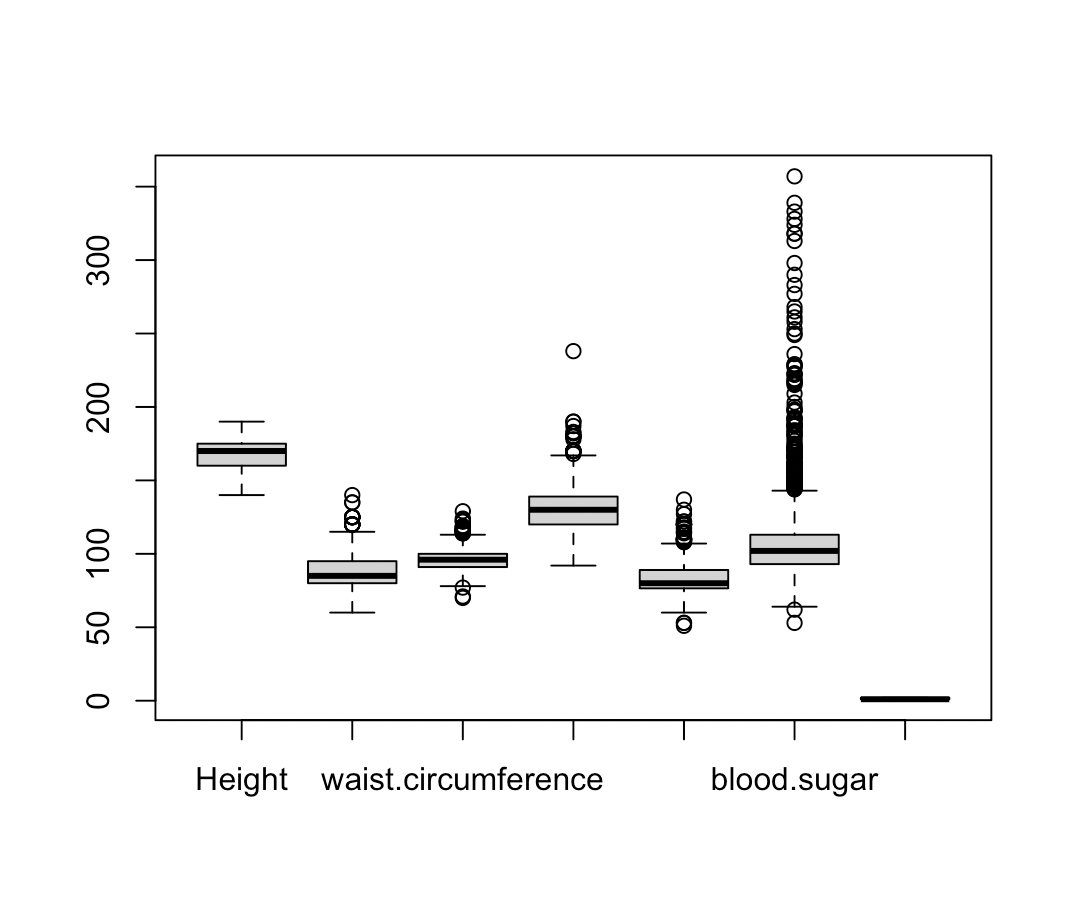
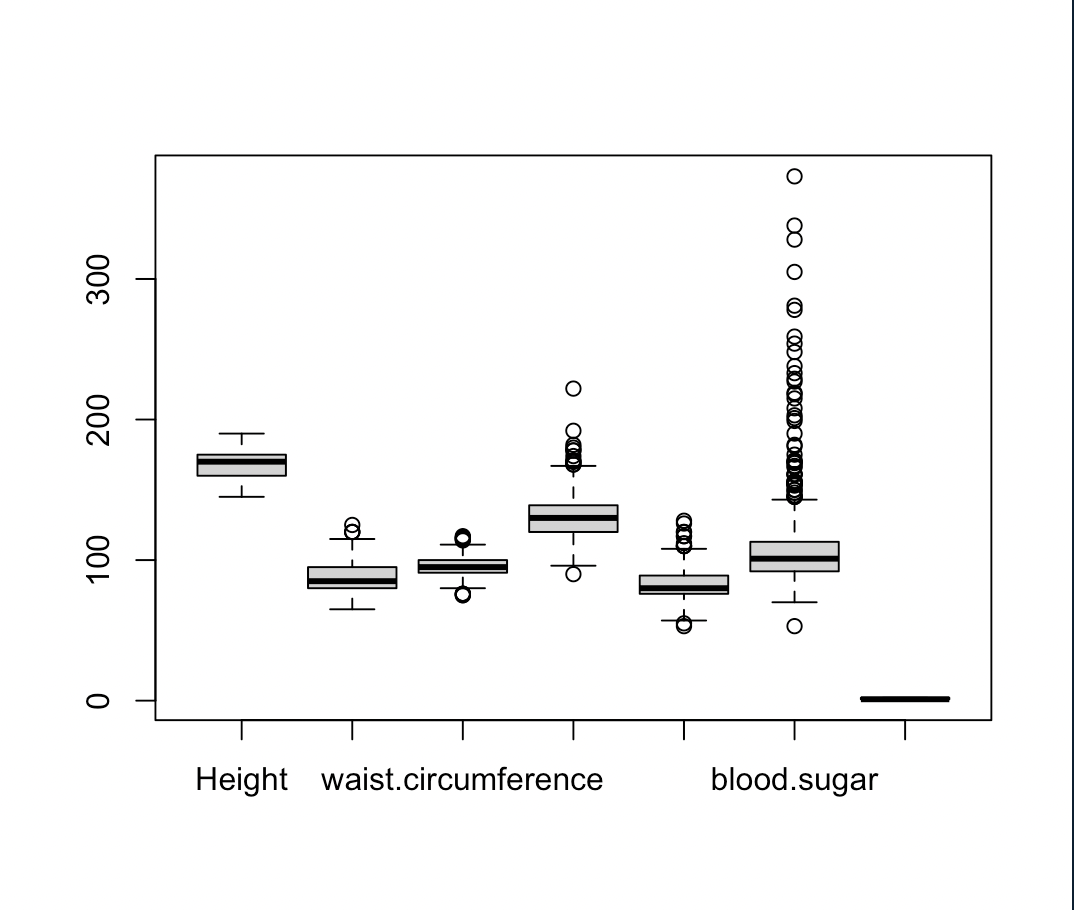
boxplot(train)
boxplot(test)boxplot(박스 플롯 = 상자 수염 그림)으로 표현한다.
 |
 |
fat_nnet <- nnet(condition~., data=train, size=10, maxit=500)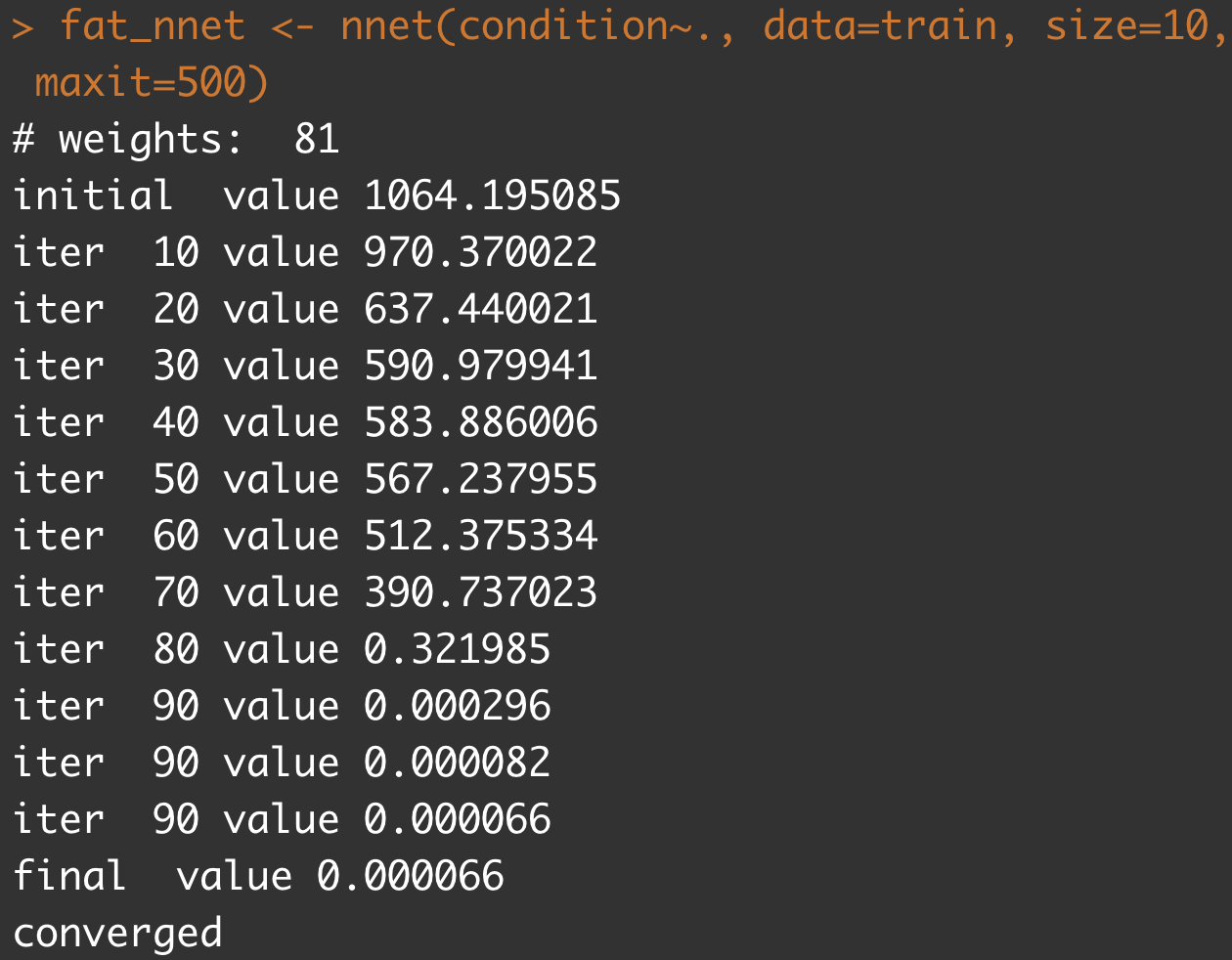
size: 은닉층 개수maxit: 반복학습의 최대 횟수. maximum number of iterations. Default 100.
출처 : https://www.rdocumentation.org/packages/nnet/versions/7.3-18/topics/nnet
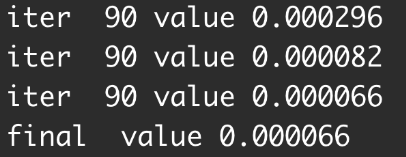
여기서 value란
- value : value of fitting criterion plus weight decay term.
(fitting criterion에 weight decay를 더한 값 → 일반적으로 값이 작을수록 학습이 잘 되었다.) - wight decay : overfitting을 피하기 위해 사용.
The fitting criterion is another synonym for loss function. Training a neural network proceeds by adjusting the weights and biases of a neural network to minimize the loss function (fitting criterion) with respect to the training data.
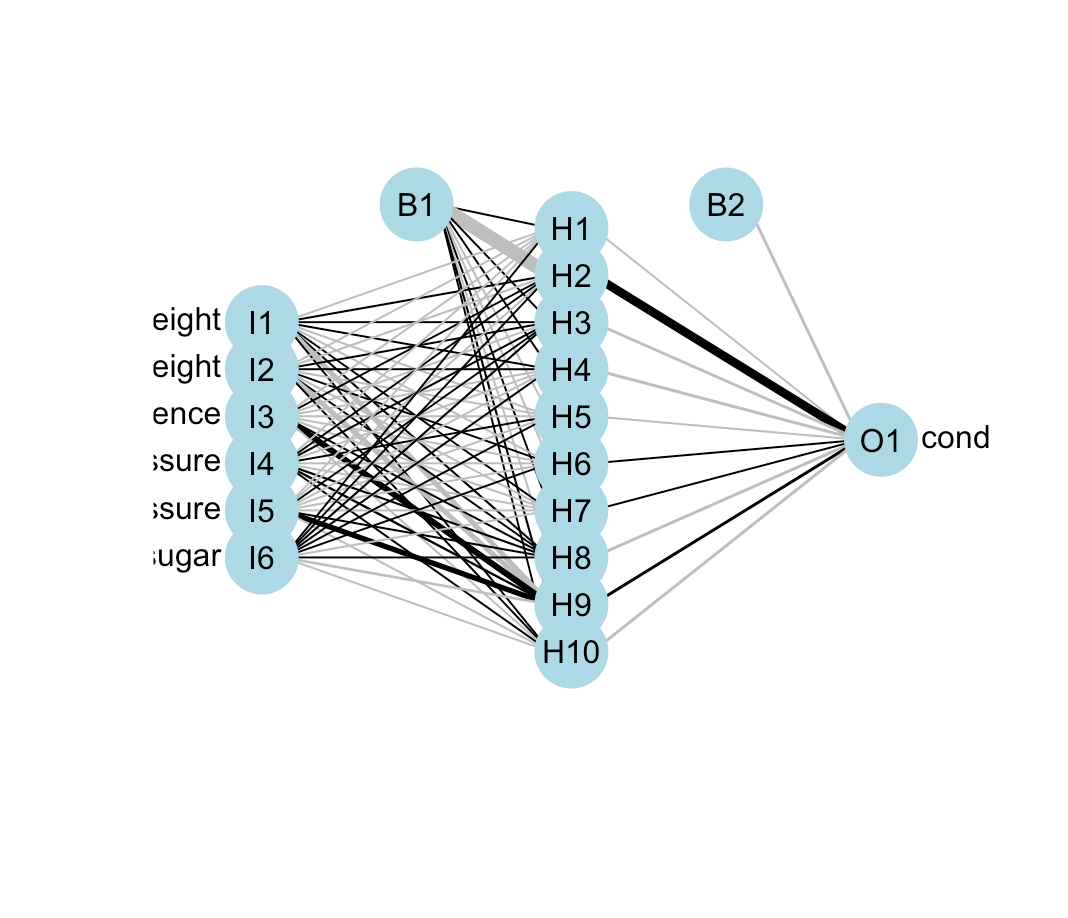
plotnet(fat_nnet)Plot a neural interpretation diagram for a neural network object
뉴럴 네트워크를 다이어그램으로 표현.
출처 : https://www.rdocumentation.org/packages/NeuralNetTools/versions/1.5.3/topics/plotnet
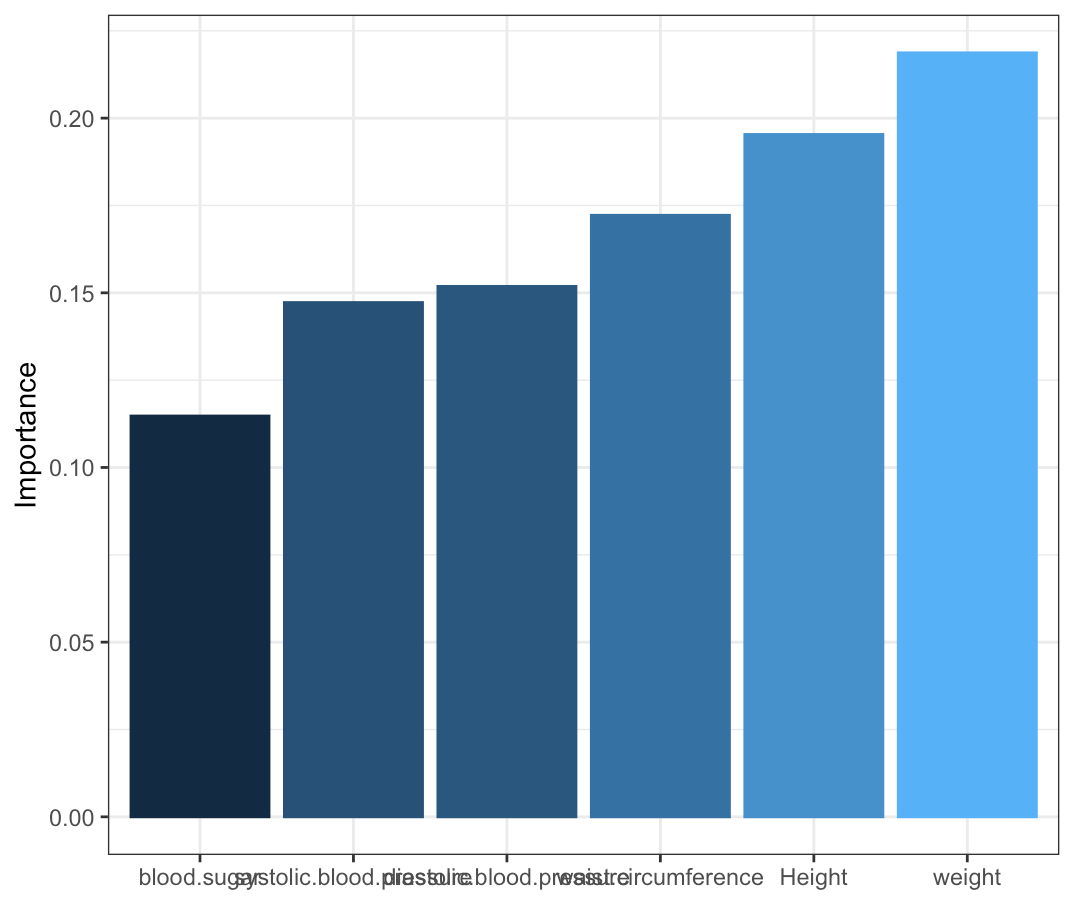
garson(fat_nnet)Relative importance of input variables in neural networks using Garson's algorithm
입력된 변수들의 상대적인 중요도 표현.
출처 : https://www.rdocumentation.org/packages/NeuralNetTools/versions/1.5.3/topics/garson
pred_nnet <- predict(fat_nnet, test, type = "class")
table(pred_nnet, test$condition)
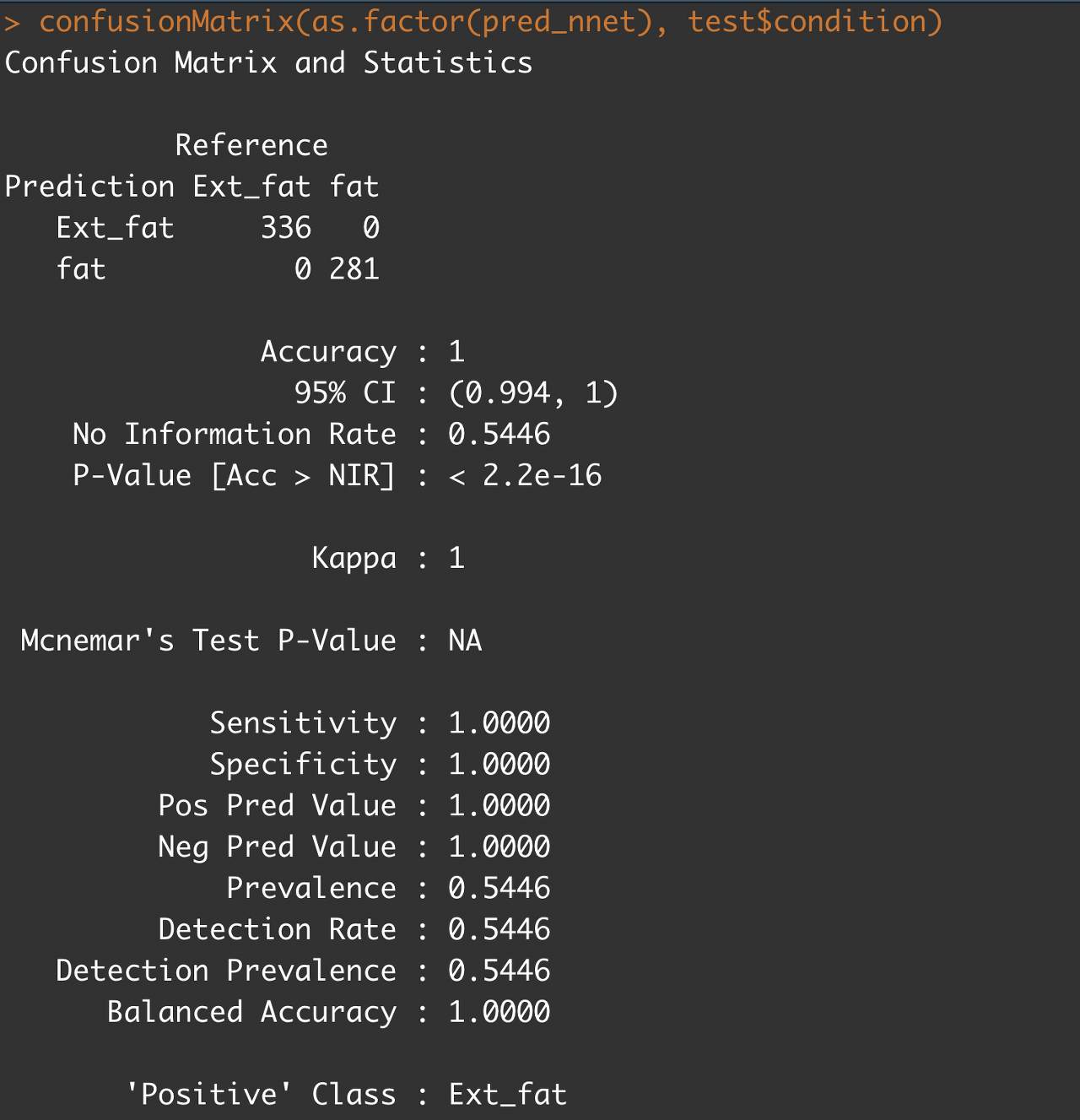
confusionMatrix(pred_nnet, test$condition)
#위의 명령어에 오류가 발생할 경우 사용
#confusionMatrix(as.factor(pred_nnet), test$condition)테스트
 |
 |
 |
|
'학부 강의 > 데이터마이닝' 카테고리의 다른 글
| 2022-11-13 데이터마이닝_7 (0) | 2022.11.13 |
|---|---|
| 2022-10-14 데이터마이닝_6 (0) | 2022.10.14 |
| 2022-09-28 데이터마이닝_4 (0) | 2022.09.28 |
| 2022-09-21 데이터마이닝_3 (1) | 2022.09.21 |
| 2022-09-20 데이터마이닝_2 (0) | 2022.09.20 |