2023. 1. 4. 13:51ㆍ학부 강의/AI 입문
1. NLP (자연어 처리)
자연어란 사람이 사용하는 언어를 지칭한다.
자연어 처리(NLP)는 컴퓨터를 이용해서 자연어를 이해, 생성하기 위한 분야다.
가. NLP 기술

보기에도 많은 기술이 사용된다.
나. 머신러닝과 NLP
머신러닝을 이용해서 NLP하는 전체 과정을 간략하게 표현한 것.
NLP를 위한 머신러닝 모델의 입력으로 사용할 대부분의 특징은 형태소 분석기와 같은 도구(software)를 통해서 제작한다.
2. 코퍼스 (Corpus)
머신러닝 모델을 학습시키기 위해서 실제 언어가 사용된 사례가 필요하다.
이에 분석에 활용할 텍스트 모음을 코퍼스라고 한다.
코퍼스의 예시로 한국어 위키피디어를 활용한 코퍼스, Naver 영화 리뷰를 활용한 코퍼스, IMDB 영화 리뷰를 활용한 코퍼스 등이 있다.
가. 학습 데이터 제작
복잡하지만 큰 흐름은 “전처리 → 벡터화 “정도라고 이해하면 된다.
(1) 코퍼스 토큰화
- 코퍼스 정제(cleaning) : 불필요한 글자(구두점, 태그, 심벌 등)를 제거하고 소문자화 한다.
- 토큰화 코퍼스 : 트큰리스트로 구성된다.
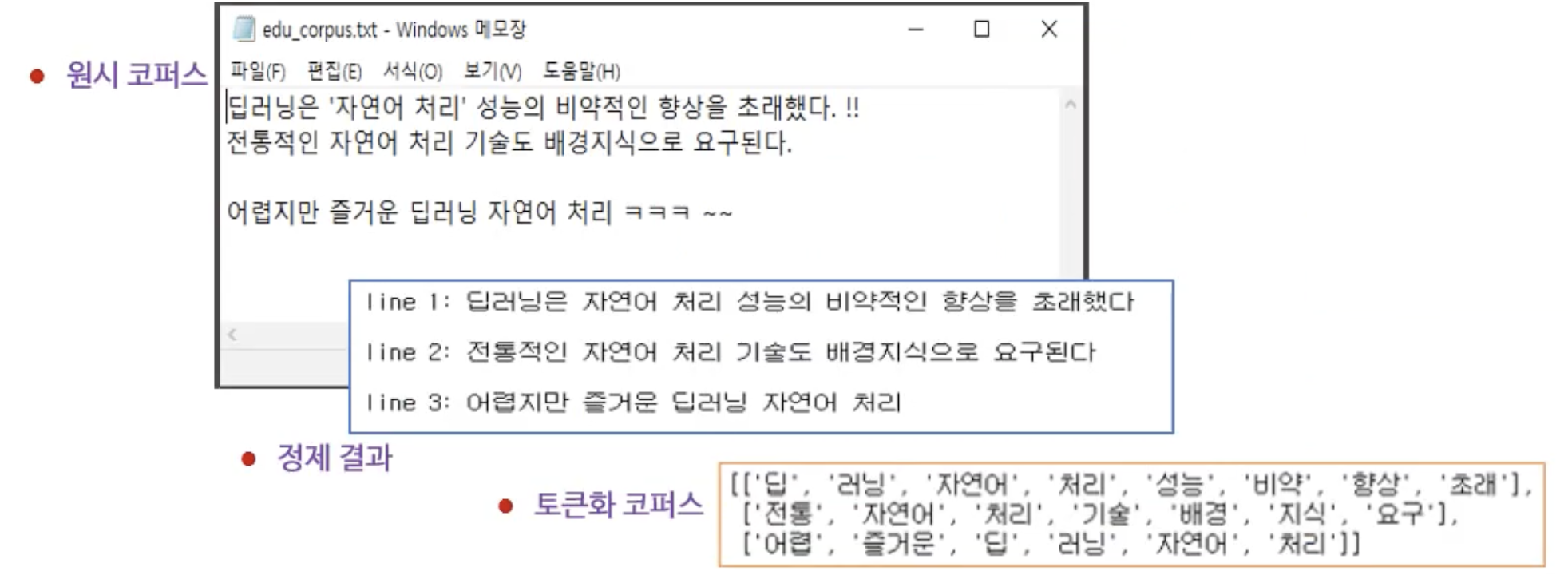
(2) 어휘집 제작

단어를 id로, id를 다시 단어로 변환할 수 있는 사전을 제작한다.
(3) 코드화 코퍼스 제작
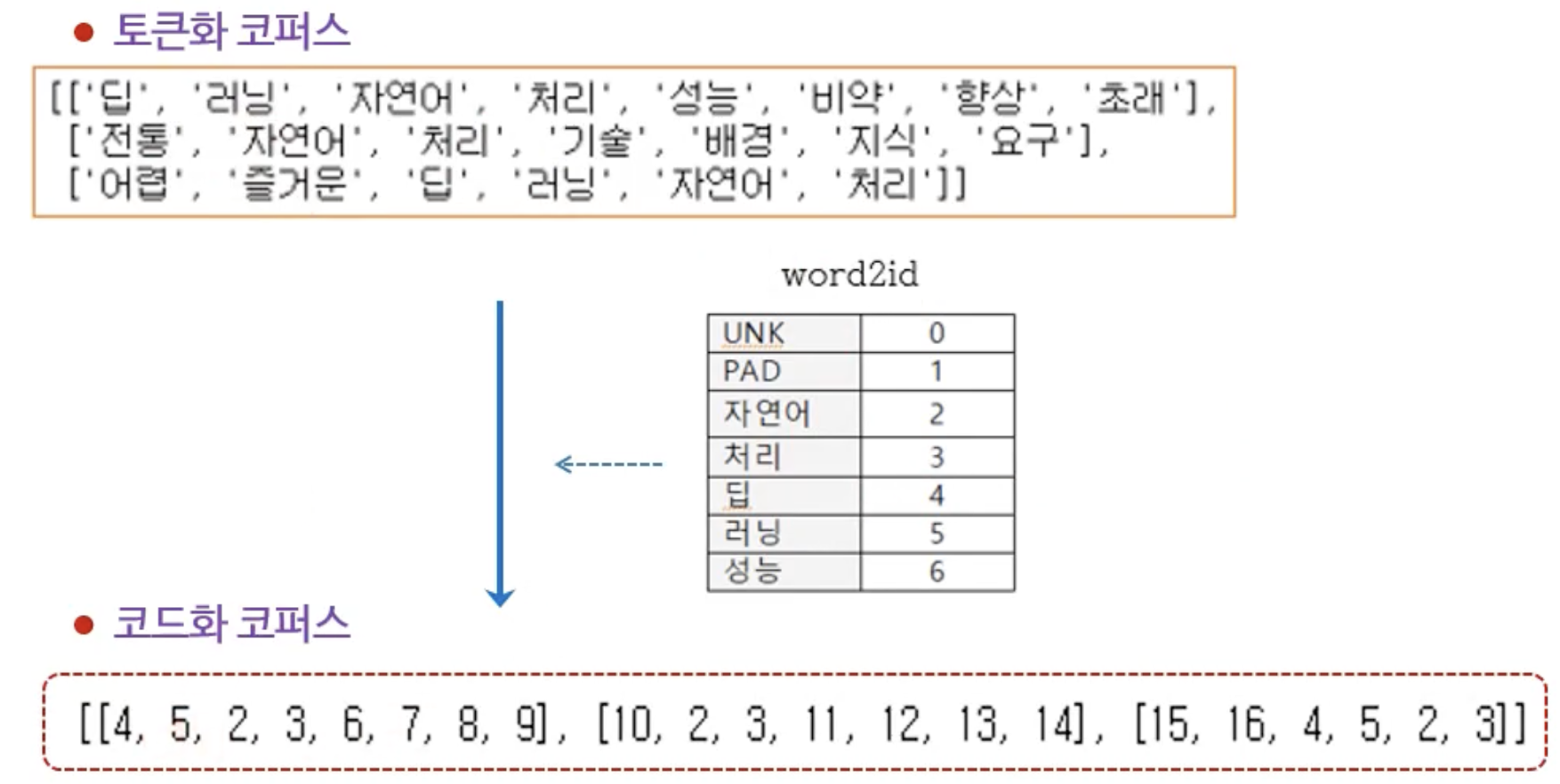
최종적으로 문장을 id로 구성된 리스트로 변환한다.
3. 단어(토큰) 표현 방식

(1) 원-핫 인코딩
- 벡터의 크기 : 어휘집의 단어의 개수에 해당하는 길이
- 1 : 벡터의 성분 중에서 단 한 개만 1
- 0 : 나머지는 모두 0
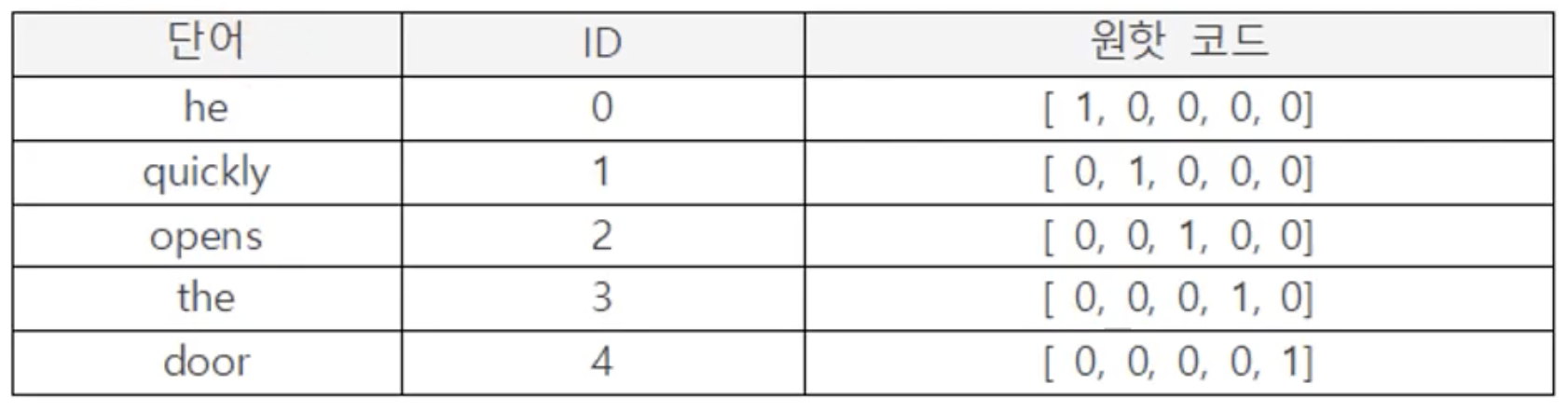
코드를 보고 단어를 식별하는 것이 용이하다.
(2) 워드 임베딩
신경망을 이용한다.
단어를 임베딩 벡터, 밀집 벡터라고 하는 벡터로 표현한다.

실제 코퍼스에선 x값에 해당하는 원-핫 코드의 길이가 무지막지하게 클 수 있기 때문에 word2Vec 기법으로 구한 크기가 비교적 작은 y값(임베딩 벡터)를 활용한다.
코드의 길이가 짧고 코드 간에 상호 유사성/연관성을 측정할 수 있다.
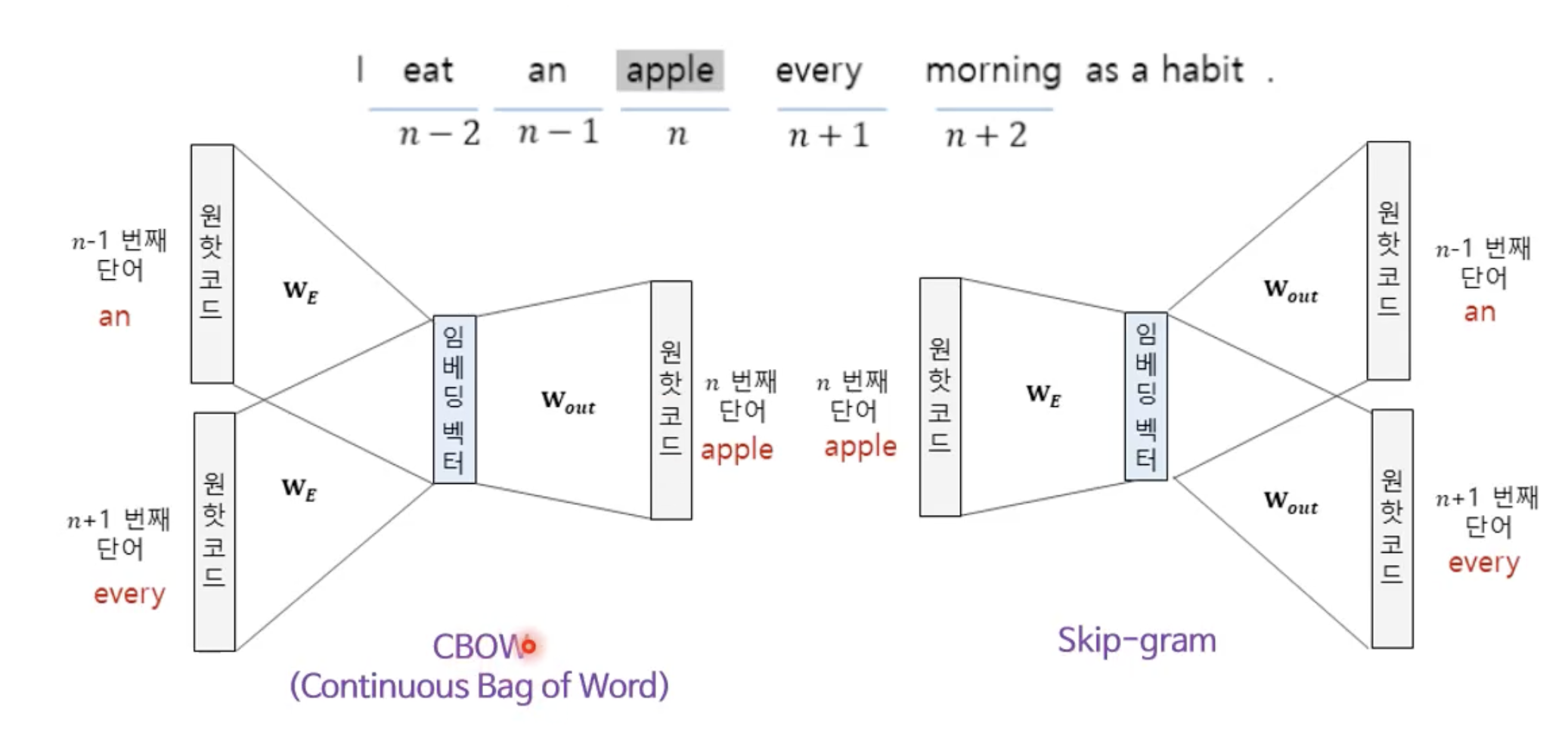
신경망은 입력된 단어와 순서상 관계가 깊은 단어를 출력하도록 훈련시킨다.
4. 언어모델 (LM)
언어모델이라 함은 언어 분석에 사용되는 일종의 확률 모델로서
- 문장이나 단어 시퀀스에 확률을 부여하거나
- 앞으로 나올 문장이나 단어의 확률을 제공한다.
가. LM의 활용
- 기계번역 시스템
: 어떤 문장에 대해 가장 큰 확률의 문장 또는 단어를 선택한다. - 텍스트 요약
: 텍스트를 구성하는 단어들 중에서 가장 큰 확률을 갖는 단어들을 모아서 구성 - 질의응답
: 특정 질의에 대해 여러 답변 중에서 가장 확률이 높은 답변으로 응답
나. LM의 구현
- RNN, LSTM, GRU 기반
: Text RNN(Vanilla RNN), Seq2Seq 모델 등 - 트랜스포머 기반
: BERT, GPT3 등
'학부 강의 > AI 입문' 카테고리의 다른 글
| 2023-01-04 AI입문_13 (0) | 2023.01.04 |
|---|---|
| 2023-01-04 AI입문12 (0) | 2023.01.04 |
| 2023-01-02 AI입문_10 (0) | 2023.01.02 |
| 2022-11-13 AI입문_9 (0) | 2022.11.13 |
| 2022-11-07 AI입문_8 (0) | 2022.11.08 |